

- 01326 375705






PFA Research delivers the market and customer insights you need to make informed decisions; saving you valuable time and reducing risk.
Just tell us what you want to know and we’ll use a mix of quantitative and qualitative market research techniques to give you the answers.
We’re proven experts at what we do, and it’s our professional interpretation and recommendations that you’ll find the most enlightening.
Call us on 01326 375705 – we’ll be delighted to help.
We’re looking for confident, versatile and well-spoken people to boost our telephone and in-field research teams. PFA Research is growing and we’re looking for more people to join our research fieldwork team on a flexible basis. Find out more...

“PFA Research have always delivered for us and that’s why we have gone back to them time and time again. I like the fact that things can be iterative and fluid in getting to the best end result.”

Salary: Full time, £28-32k depending on experience Location: Hybrid role requiring regular attendance at head office in Penryn, Cornwall and occasional visits to our office in Stockport,... Read More

The Cornwall Business Observatory is a new online space initiated by PFA Research to describe Cornwall’s economy and business landscape through curated research and up-to-date... Read More
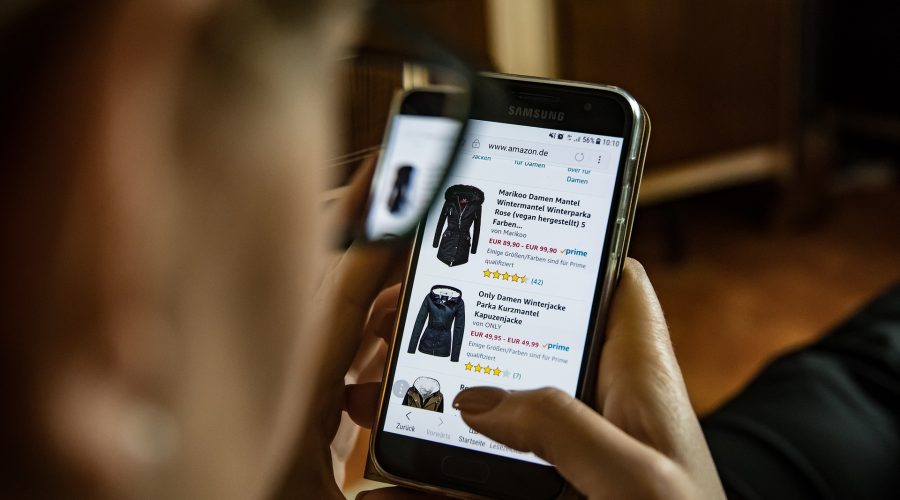
There’s growing evidence that consumers are trying to act sustainably and that they expect the same from businesses. So when it comes to buying, they’re... Read More
![]()
All research is carried out in accordance with the UK Market Research Society Code of Conduct.
We manage our research projects to ISO9001 Quality Management standards.